
背景介绍:DeepSeek 为什么会有两个旗舰模型?
红烁AI 培训,红烁 AI 中转站为您整理:2025年初,DeepSeek 接连发布了两款引发全球关注的大语言模型——DeepSeek V3 和 DeepSeek R1。前者以极低的训练成本和媲美 GPT-4o 的综合能力震惊业界,后者则凭借在数学、代码和逻辑推理上的卓越表现,直接对标 OpenAI o1。
很多人看到这两个名字会产生困惑:它们是迭代关系吗?哪个更强?该用哪个?事实上,R1 和 V3 并非简单的”新旧版本”关系,而是两条不同技术路线的产物,分别针对不同的核心问题而设计。理解这一点,是正确使用 DeepSeek 系列模型的前提。
核心区别一:模型定位与设计目标
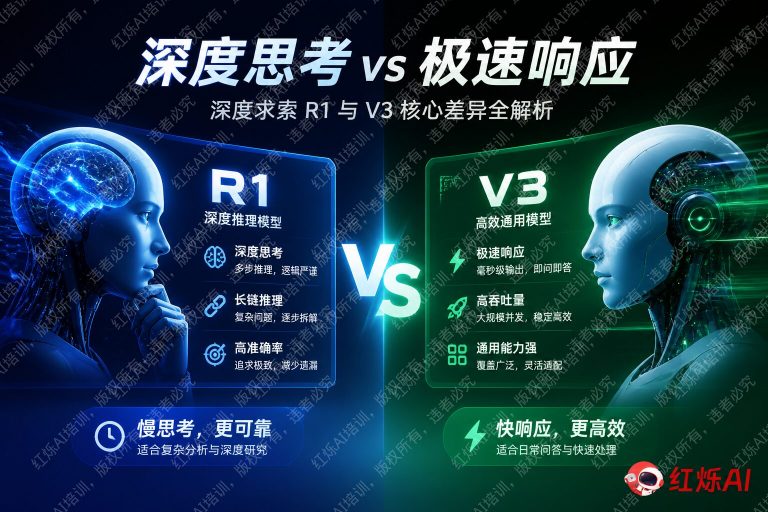
DeepSeek V3:通用能力的极致压缩
DeepSeek V3 是一款通用大语言模型(General-Purpose LLM),其设计目标是在尽可能低的推理成本下,覆盖尽可能广泛的任务类型。它采用了 MoE(Mixture of Experts,混合专家)架构,总参数量达 671B,但每次推理仅激活约 37B 参数,实现了性能与效率的平衡。
V3 的核心优势在于:
- 多任务泛化能力强,覆盖写作、翻译、问答、代码生成等主流场景
- 响应速度快,延迟低,适合对话类和实时交互类应用
- 训练成本极低(官方披露约 557 万美元),性价比极高
- 上下文窗口达 128K tokens,适合长文档处理
DeepSeek R1:为”深度思考”而生
DeepSeek R1 是一款推理增强型模型(Reasoning-Focused LLM),其设计目标是解决复杂的、需要多步骤逻辑推导的问题。R1 的核心创新在于引入了强化学习(Reinforcement Learning)训练范式,让模型在没有大量人工标注数据的情况下,通过自我博弈和奖励信号学会”如何思考”。
R1 的核心优势在于:
- 在数学竞赛题、复杂代码调试、科学推理等任务上表现突出
- 具备显式的”思维链(Chain-of-Thought)”输出,推理过程透明可查
- 在 AIME、MATH-500 等权威基准测试上达到或超越 OpenAI o1 水平
- 支持蒸馏版本(1.5B 至 70B),可在本地设备部署
核心区别二:训练方式的根本差异
这是 R1 与 V3 最本质的技术分野。
DeepSeek V3 沿用了主流的监督微调(SFT)+ 人类反馈强化学习(RLHF)路线,通过海量高质量数据进行预训练,再经过指令微调和偏好对齐,最终形成一个”听话、全能、流畅”的助手模型。这条路线成熟稳定,是当前大多数顶级模型的标准做法。
DeepSeek R1 则走了一条更激进的路:研究团队首先尝试了纯强化学习(Pure RL)训练,即不依赖人工标注的思维链数据,直接让模型通过结果奖励信号自主涌现出推理能力。这一实验(内部称为 R1-Zero)证明了 RL 可以让模型自发产生”反思”和”验证”行为。最终发布的 R1 版本在此基础上结合了少量冷启动数据,进一步提升了输出的可读性和稳定性。
这种训练方式的差异,直接导致了两个模型在输出风格上的显著不同:V3 的回答简洁直接,R1 的回答则会包含一段较长的内部推理过程(thinking process),最终再给出结论。
核心区别三:性能基准对比
从主流评测基准来看,两款模型各有侧重:
- 数学推理(AIME 2024):R1 得分约 79.8%,V3 约 39.2%,R1 大幅领先
- 代码能力(Codeforces):R1 评级约 2029,V3 约 1696,R1 更强
- 综合知识(MMLU):V3 约 88.5%,R1 约 90.8%,两者接近
- 中文理解与生成:V3 表现更自然流畅,R1 有时因推理模式导致输出冗长
- 响应延迟:V3 明显快于 R1,因为 R1 需要额外的思考步骤
简而言之:需要”算得准”,选 R1;需要”说得好、回得快”,选 V3。
实际应用:如何根据场景选择模型?
适合使用 DeepSeek R1 的场景
- 解数学题、物理题、竞赛题等需要严密推导的任务
- 复杂算法设计与代码 Debug,尤其是逻辑错误排查
- 法律条文分析、合同逻辑审查等需要多步骤判断的专业场景
- 科研辅助,如实验方案推演、论文逻辑验证
- 需要模型”展示思考过程”以便人工审核的高风险决策场景
适合使用 DeepSeek V3 的场景
- 日常对话助手、客服机器人等对响应速度要求高的应用
- 内容创作:文章撰写、营销文案、邮件起草
- 代码补全与常规开发辅助(非复杂算法类)
- 多语言翻译与本地化处理
- 长文档摘要、知识库问答等 RAG 应用
常见问题 FAQ
Q1:R1 是基于 V3 训练的吗?
是的。DeepSeek R1 以 DeepSeek V3 作为基础模型(Base Model),在其之上通过强化学习进行推理能力的专项强化。可以理解为:V3 是”底座”,R1 是在这个底座上进行了”深度思考能力改造”的专用版本。
Q2:R1 比 V3 更新,是否意味着 R1 全面更强?
不是。R1 在推理任务上更强,但在通用对话流畅度、响应速度和部分创意写作任务上,V3 反而更合适。两者是互补关系,而非替代关系。
Q3:DeepSeek R1 的蒸馏版本和完整版有什么区别?
DeepSeek 官方发布了基于 R1 蒸馏的多个小模型(1.5B、7B、8B、14B、32B、70B),这些模型通过知识蒸馏继承了 R1 的推理能力,可在本地或消费级 GPU 上运行。完整版 R1(671B)能力更强,但需要专业推理基础设施支持。
Q4:API 调用时如何区分使用哪个模型?
在 DeepSeek 官方 API 中,对应的模型名称分别为 deepseek-chat(对应 V3)和 deepseek-reasoner(对应 R1)。调用 R1 时,响应中会包含 reasoning_content 字段,记录模型的思考过程。
Q5:两个模型的价格有差异吗?
有差异。由于 R1 需要更多计算资源来完成推理过程,其 API 调用价格通常高于 V3。具体定价以 DeepSeek 官方平台公布为准,建议在选型时将成本因素纳入考量。
总结
DeepSeek R1 与 V3 的核心区别,本质上是推理深度与通用效率之间的取舍。V3 是一款经过精心工程优化的全能型模型,以极低成本提供接近顶级的综合能力;R1 则是一次对”机器如何思考”的深度探索,通过强化学习让模型真正学会了推理,而非仅仅模仿推理的形式。
对于大多数开发者而言,日常应用首选 V3,遇到需要严密推导的硬核任务时切换 R1,是最务实的使用策略。随着 DeepSeek 持续迭代,两条技术路线的融合也值得期待——未来的模型或许能同时兼顾 V3 的效率与 R1 的深度。
想了解更多AI工具和技巧?欢迎访问红烁AI 培训,红烁 AI 中转站,获取最新AI资讯和实用教程。