
背景:DeepSeek R1 和 V3 为什么容易混淆?
红烁AI 培训,红烁 AI 中转站为您整理:2024年底至2025年初,DeepSeek接连发布了V3和R1两款模型,在全球AI社区引发强烈反响。两款模型都来自同一家公司,名字相近,性能都很出色,这让很多用户在实际使用时产生困惑:到底该用哪一个?
混淆的根源在于,大多数人习惯用”更新 = 更好”的逻辑来选择模型。但DeepSeek R1并不是V3的升级版,两者走的是完全不同的技术路线,解决的是不同类型的问题。搞清楚如何区分DeepSeek R1和V3的使用场景,本质上是搞清楚两种AI范式的差异。
核心差异:一句话理解两款模型
在深入细节之前,先给出一个最直观的定位:
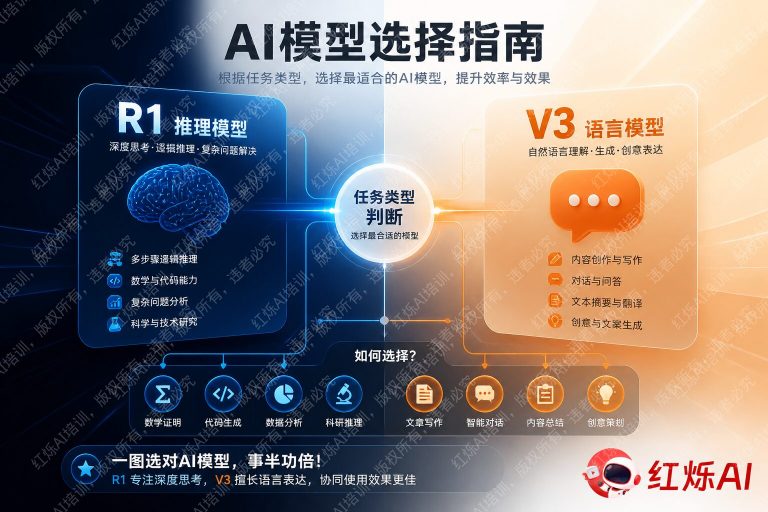
- DeepSeek V3:通用型语言模型,快速、流畅、覆盖面广,适合大多数日常任务。
- DeepSeek R1:推理增强型模型,慢而深思,擅长需要多步骤逻辑推导的复杂任务。
如果把AI模型比作人,V3像一位博学的通才,能快速给出高质量答案;R1则像一位严谨的数学家,会在回答之前把整个推理过程完整走一遍。
技术架构对比
DeepSeek V3 的技术特点
DeepSeek V3 是一款基于 MoE(混合专家架构)的大规模语言模型,总参数量达 671B,但每次推理只激活约 37B 参数。这种设计让它在保持高性能的同时,大幅降低了推理成本。V3 的训练数据覆盖代码、数学、多语言文本等多个领域,是一款真正意义上的通用基础模型。
V3 的核心优势在于响应速度快、输出流畅、上下文理解能力强,在多项公开基准测试中与 GPT-4o、Claude 3.5 Sonnet 处于同一梯队。
DeepSeek R1 的技术特点
DeepSeek R1 是一款专门针对推理能力优化的模型,其最大的技术亮点是引入了强化学习驱动的思维链(Chain-of-Thought)训练机制。R1 在生成最终答案之前,会先输出一段完整的内部推理过程(thinking token),这个过程类似于人类”打草稿”。
正是这种机制,让 R1 在数学竞赛题、逻辑推理、复杂代码调试等任务上表现远超同类模型。在 AIME 2024 数学竞赛基准上,R1 的得分与 OpenAI o1 相当,这在开源模型中极为罕见。
使用场景深度对比
适合使用 DeepSeek V3 的场景
- 内容创作与写作:撰写文章、营销文案、邮件、报告,V3 的语言流畅度和创意表达更胜一筹。
- 日常问答与信息检索:快速获取知识、解释概念、总结文档,V3 响应速度更快,体验更好。
- 多轮对话与客服场景:需要保持上下文连贯性的长对话,V3 的对话管理能力更稳定。
- 代码补全与常规编程:日常的函数编写、代码注释、简单 bug 修复,V3 完全胜任且速度更快。
- 翻译与多语言处理:V3 的多语言训练数据更丰富,翻译质量和语言切换更自然。
- 高并发 API 调用:对于需要大量并发请求的应用,V3 的低延迟特性更具优势。
适合使用 DeepSeek R1 的场景
- 数学与竞赛题求解:高中竞赛、大学数学、考研数学等需要严格推导的题目,R1 是首选。
- 复杂逻辑推理:多条件约束问题、逻辑谜题、因果分析,R1 的思维链能有效避免跳步错误。
- 算法设计与复杂代码调试:设计复杂数据结构、排查深层 bug、优化算法时间复杂度,R1 的逐步推理能发现 V3 容易忽略的细节。
- 科学研究辅助:物理建模、化学反应推导、统计分析方案设计,R1 的严谨性更符合学术要求。
- 法律与合规分析:需要逐条梳理条款、分析多方利益关系的复杂法律问题,R1 的结构化推理更可靠。
- 需要可解释性的决策支持:当你不只需要答案,还需要完整推理过程作为依据时,R1 的思维链输出天然满足这一需求。
实际应用:用一个例子感受差异
假设你问两款模型同一个问题:“一个水池有两个进水管,A管单独注满需要6小时,B管单独注满需要4小时,同时开启多少小时能注满?”
V3 的表现:直接给出答案”2.4小时”,并附上简洁的计算过程,响应迅速,适合快速验证。
R1 的表现:先输出完整的思维链——定义变量、建立方程、逐步求解、验证结果——最后给出答案。整个过程更长,但每一步都有据可查,出错概率极低。
对于这道简单题,V3 完全够用。但如果换成一道需要分类讨论、含有多个约束条件的竞赛题,R1 的优势就会显著体现出来。
常见问题 FAQ
Q1:R1 是 V3 的升级版吗?
不是。R1 和 V3 是并行发布的两条产品线,分别针对不同需求优化。R1 在推理任务上更强,但在通用性和响应速度上不如 V3。选择哪个取决于你的具体任务,而不是版本号。
Q2:R1 速度慢多少?会影响使用体验吗?
由于 R1 需要生成思维链 token,响应时间通常是 V3 的 2-4 倍。对于需要实时交互的场景(如聊天机器人、实时客服),这个延迟会影响体验。但对于离线批处理任务或对准确性要求极高的场景,这个代价完全值得。
Q3:普通用户日常使用,选哪个更合适?
绝大多数日常场景选 V3 即可。写作、问答、翻译、普通编程,V3 的性能已经非常出色,且体验更流畅。只有当你明确需要处理数学推理、复杂逻辑或需要可解释的推导过程时,才切换到 R1。
Q4:两款模型的 API 定价有差异吗?
有差异。由于 R1 的推理计算量更大,其 API 调用成本通常高于 V3。在构建生产级应用时,建议根据任务类型做路由分发:简单任务走 V3,复杂推理任务走 R1,这样能在成本和效果之间取得最佳平衡。
Q5:有没有办法让 V3 也具备 R1 的推理能力?
可以通过提示词工程(如 Chain-of-Thought prompting)引导 V3 进行逐步推理,效果会有所提升,但仍无法达到 R1 的水平。R1 的推理能力来自底层训练机制,不是提示词能完全复现的。
总结:选择模型的决策框架
区分 DeepSeek R1 和 V3 的使用场景,核心逻辑只有一条:任务是否需要多步骤、可验证的逻辑推导?
如果答案是否,选 V3——更快、更流畅、覆盖面更广。如果答案是是,选 R1——更严谨、更可靠、推理过程透明可查。
两款模型并非竞争关系,而是互补关系。在实际的 AI 应用开发中,最优策略往往是根据任务类型动态路由,让 V3 处理高频通用请求,让 R1 专注于高价值的复杂推理任务。这样既能控制成本,又能保证关键任务的准确性。
随着 DeepSeek 持续迭代,两条产品线的边界可能会进一步演化,但”通用效率 vs 深度推理”这一核心分野,在可预见的未来仍将是选择模型的第一判断维度。
想了解更多AI工具和技巧?欢迎访问红烁AI 培训,红烁 AI 中转站,获取最新AI资讯和实用教程。