
背景:DeepSeek为什么同时推出R1和V3?
红烁AI 培训,红烁 AI 中转站为您整理:2024年底至2025年初,DeepSeek接连发布了两款引发全球关注的大语言模型——DeepSeek-V3和DeepSeek-R1。前者以极低的训练成本对标GPT-4o,后者则在数学、代码和逻辑推理基准上直逼OpenAI o1。两款模型几乎同期亮相,却定位截然不同,这让很多开发者产生了疑问:它们的架构到底有什么本质区别?该怎么选?
要回答这个问题,需要从模型的设计目标说起。V3的目标是构建一个高效、通用的基础模型,覆盖尽可能广泛的任务;而R1的目标是打造一个具备深度推理能力的思考型模型,专注于需要多步骤逻辑链的复杂问题。目标不同,架构选择自然也不同。
核心架构对比:V3与R1的底层差异
1. 基础架构:都用MoE,但实现方式不同
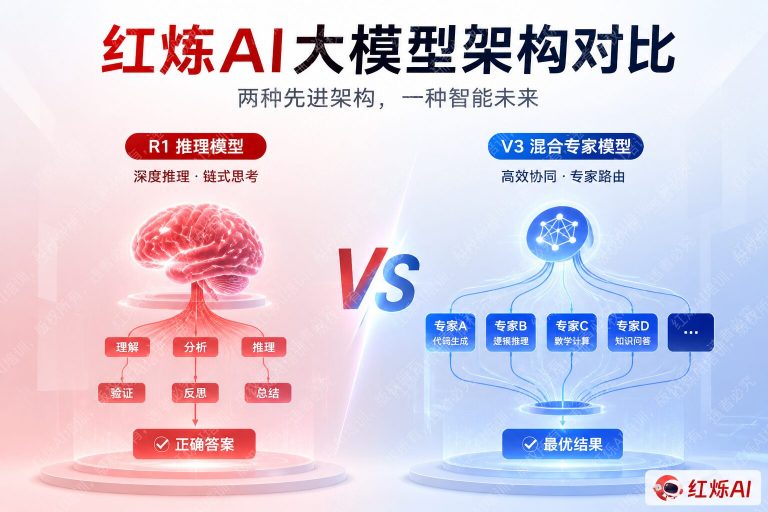
DeepSeek V3和R1都采用了混合专家模型(Mixture of Experts,MoE)架构,但两者的出发点和优化重点存在明显差异。
DeepSeek-V3拥有671B总参数,每次推理激活约37B参数。它在MoE设计上引入了两项关键创新:
- 多头潜在注意力(MLA,Multi-head Latent Attention):通过低秩压缩键值缓存,大幅降低推理时的显存占用,使长上下文处理更高效。
- DeepSeekMoE架构:将专家细粒度拆分,并引入共享专家机制,在保证模型容量的同时减少专家间的知识冗余,提升参数利用率。
- 无辅助损失的负载均衡策略:V3创新性地通过动态偏置调整实现专家负载均衡,避免了传统辅助损失对模型性能的干扰。
DeepSeek-R1的基础同样源自MoE架构(其底座来自V3系列),但R1的架构重心不在于扩展参数效率,而在于如何让模型学会”思考”。
2. 训练范式:这是R1与V3最本质的区别
这是两款模型最核心的分野。
DeepSeek-V3采用的是标准的预训练 + 监督微调(SFT)+ 强化学习对齐(RLHF)流程。它在约14.8万亿token的高质量数据上完成预训练,随后通过SFT和基于人类反馈的强化学习提升指令遵循能力和安全性。这是目前主流大模型的标准路径。
DeepSeek-R1则走了一条更激进的路:以强化学习为核心驱动力,让模型自主涌现出推理能力。具体来说,R1的训练分为几个关键阶段:
- 冷启动阶段:用少量高质量的长思维链(Chain-of-Thought)数据对基础模型进行初步微调,帮助模型建立基本的推理格式。
- 面向推理的强化学习(RL):使用基于规则的奖励信号(如答案正确性、格式规范性)进行大规模强化学习训练,模型在这一阶段自主学会了反思、验证和回溯等推理策略。
- 拒绝采样 + 全场景SFT:从RL训练的模型中采样高质量推理数据,结合通用能力数据进行混合微调,平衡推理能力与通用能力。
- 全场景RL对齐:最终阶段针对有用性和安全性进行综合强化学习对齐。
这种训练方式带来了一个令人惊喜的现象:R1在强化学习过程中自发涌现出了”顿悟时刻”(Aha Moment)——模型会在解题过程中主动停下来重新审视自己的思路,这种行为并非人为设计,而是RL训练的自然结果。
3. 推理机制:快思考 vs 慢思考
借用诺贝尔经济学奖得主丹尼尔·卡尼曼的框架来理解:V3更像系统1(快思考),R1更像系统2(慢思考)。
V3在生成回答时直接输出结果,响应速度快,适合对延迟敏感的应用场景。R1则会在正式输出答案之前,生成一段较长的内部思维链(<think>标签内的内容),在这个过程中进行探索、验证和修正,最终给出更可靠的答案。
这意味着R1的输出token数量远多于V3,推理延迟更高,但在复杂问题上的准确率也显著更高。
4. 蒸馏版本:R1的独特产物
DeepSeek还基于R1的推理能力,发布了一系列蒸馏小模型(1.5B、7B、8B、14B、32B、70B),将R1的思维链能力迁移到更小的稠密模型(如Qwen、Llama架构)上。这是V3体系中没有的产物,也体现了R1在推理能力可迁移性上的独特价值。
实际应用:如何根据场景选择V3还是R1?
理解了架构差异,选型就变得清晰了:
- 选V3的场景:内容创作、文本摘要、多轮对话、代码补全、知识问答、对响应速度有要求的生产环境API调用。
- 选R1的场景:竞赛级数学题求解、复杂算法设计、需要严格逻辑推导的法律/金融分析、科学研究辅助、对准确性要求高于速度的批处理任务。
- 选R1蒸馏版的场景:本地部署、边缘计算、需要推理能力但资源受限的环境(如14B蒸馏版在消费级GPU上即可运行)。
值得注意的是,在通用能力测试中,V3的写作、指令遵循和多语言能力往往优于R1,因为R1的训练数据更聚焦于推理任务。如果你的应用场景是综合性的,V3通常是更均衡的选择。
常见问题 FAQ
Q1:R1是基于V3训练的吗?
R1和V3共享相似的基础架构设计(MLA + DeepSeekMoE),但R1并非直接在V3权重上微调而来。DeepSeek论文中描述的R1训练流程是从一个基础模型(Base Model)出发,通过多阶段RL训练得到的。两者是”兄弟关系”而非”父子关系”。
Q2:为什么R1在某些基准上比V3强,但实际使用感觉差不多?
基准测试(如AIME数学竞赛、Codeforces算法题)专门针对R1擅长的深度推理场景设计。在日常使用中,大多数问题并不需要多步骤推理,V3的快速响应反而体验更好。R1的优势在”难题”上,而非”所有题”上。
Q3:R1的思维链内容可以关闭吗?
通过API调用时,思维链内容(<think>部分)默认不返回给用户,只返回最终答案。但思维链的计算过程仍然发生,会影响响应时间和token消耗。部分平台提供了”不带思考”的R1调用模式,但这会显著降低其在复杂任务上的表现。
Q4:DeepSeek V3和R1哪个更”便宜”?
以官方API定价为参考,V3的输入/输出token价格通常低于R1,且R1因为会生成更长的思维链,实际每次调用消耗的token数量更多。综合来看,处理同一个复杂问题,R1的实际费用可能是V3的数倍。
Q5:未来DeepSeek会合并这两条产品线吗?
从行业趋势来看,OpenAI已经在GPT-4o中整合了部分o1的推理能力,形成”自适应思考深度”的方向。DeepSeek很可能也会在未来版本中探索类似路径——根据问题复杂度动态决定是否启用深度推理模式,而不是维持两条独立的产品线。
总结
DeepSeek R1与V3的架构区别,本质上是通用能力与深度推理能力之间的设计取舍。V3通过精心设计的MoE架构和海量数据预训练,构建了一个高效、均衡的通用基础模型;R1则通过以强化学习为核心的创新训练范式,让模型自主涌现出人类式的逻辑推理能力。
两者并非竞争关系,而是互补关系。理解它们的架构差异,不仅能帮助你做出更好的模型选型决策,也能让你更深刻地理解当前大模型技术演进的两条主要路径:做大做强的通用基础模型,以及通过强化学习解锁更深层推理能力的专用模型。这两条路,DeepSeek都走在了世界前列。
想了解更多AI工具和技巧?欢迎访问红烁AI 培训,红烁 AI 中转站,获取最新AI资讯和实用教程。