
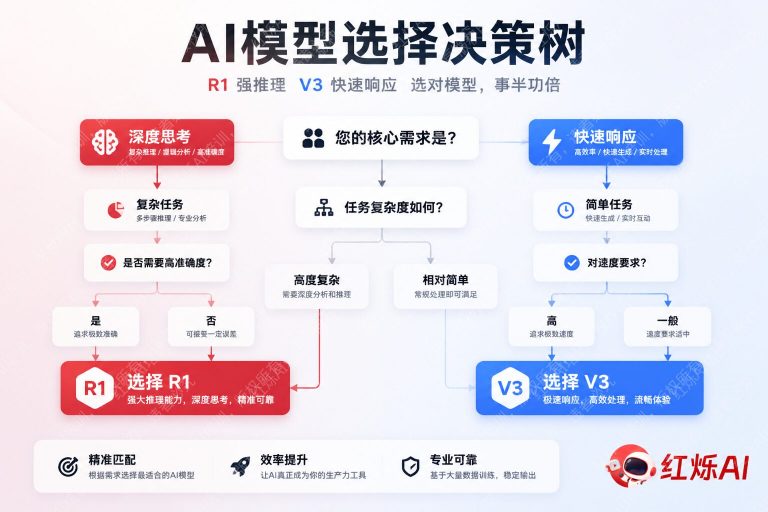
背景:DeepSeek R1和V3到底有什么不同
红烁AI 培训,红烁 AI 中转站为您整理:DeepSeek在短时间内推出了两款定位截然不同的旗舰模型——R1和V3,让不少开发者和普通用户陷入选择困惑。表面上看,两者都能回答问题、写代码、做分析,但底层设计逻辑差异很大,直接决定了它们各自擅长的任务类型。
DeepSeek V3是一款基于混合专家架构(MoE)的通用大语言模型,参数规模达到671B,但每次推理只激活约37B参数,兼顾了性能与效率。它的训练重点是广泛的知识覆盖和流畅的语言生成,响应速度快,适合高吞吐量的应用场景。
DeepSeek R1则是专门针对推理能力优化的模型,采用了强化学习训练范式(类似OpenAI o1的技术路线),在回答之前会进行”链式思考”(Chain-of-Thought),把复杂问题拆解成多个推理步骤再给出答案。这个过程更慢,但在逻辑密集型任务上准确率显著更高。
简单来说:V3是快而博的通才,R1是慢而精的推理专家。理解这一点,是做出正确选择的基础。
核心差异对比:从四个维度看清两款模型
1. 推理深度
R1在推理深度上有明显优势。它会在内部生成一段”思考过程”,对问题进行多步分解,再输出最终答案。这种机制在数学证明、逻辑谜题、代码调试等场景下能大幅减少错误。V3则倾向于直接生成答案,推理链条较短,在简单问题上够用,但遇到需要多步骤验证的复杂问题时容易出错。
2. 响应速度
V3的响应速度明显快于R1。由于R1需要先完成内部推理再输出,首token延迟更高,整体生成时间更长。如果你的应用对实时性要求高,比如聊天机器人、实时翻译、内容草稿生成,V3是更合适的选择。
3. 语言生成质量
在创意写作、营销文案、多语言翻译等纯语言生成任务上,V3的表现更自然流畅。它的训练数据覆盖更广,语言风格更多样。R1的输出有时会因为过度”理性化”而显得生硬,不适合需要情感温度的内容。
4. 成本与资源消耗
通过API调用时,R1的单次调用成本通常高于V3,因为推理步骤更多、token消耗更大。对于预算敏感的项目,在不需要深度推理的场景下优先选V3,可以有效控制成本。
实际应用:按任务类型的选型决策
适合选DeepSeek R1的任务
- 数学与科学计算:解方程、数学证明、物理推导、统计分析。R1的逐步推理能力能有效避免中间步骤出错,最终答案可靠性更高。
- 复杂代码调试:当你需要找出一段代码的逻辑漏洞,或者理解一个复杂算法的执行路径时,R1能更系统地追踪问题根源,给出有据可查的修复方案。
- 逻辑推理与谜题:法律条文分析、合同条款解读、逻辑谜题求解。这类任务需要严格的条件推导,R1的链式思考机制天然契合。
- 学术研究辅助:文献论点梳理、研究方法评估、实验设计审查。R1能更好地处理需要批判性思维的学术场景。
- 多步骤规划:项目拆解、决策树分析、风险评估。当任务本身需要”先想清楚再行动”时,R1的推理优势就能体现出来。
适合选DeepSeek V3的任务
- 内容创作与写作:博客文章、产品描述、社交媒体文案、故事创作。V3的语言生成更自然,风格更灵活,创意表达能力更强。
- 日常对话与问答:知识查询、百科解释、日常咨询。V3响应快、覆盖广,处理这类任务性价比最高。
- 代码生成(非调试):根据需求从零生成代码片段、脚手架搭建、API调用示例。V3在代码生成速度和覆盖语言广度上表现优秀。
- 翻译与多语言处理:文档翻译、本地化内容改写、多语言客服回复。V3的多语言能力经过充分训练,流畅度更高。
- 摘要与信息提取:长文档摘要、会议纪要整理、新闻要点提取。这类任务不需要深度推理,V3的速度优势更有价值。
混合使用策略
在一些复杂工作流中,两款模型可以配合使用。例如:先用V3快速生成一份代码草稿,再用R1对关键逻辑部分进行审查和调试;或者用V3生成多个方案选项,再用R1对每个方案进行可行性推理评估。这种”V3起草+R1审核”的组合,在保证质量的同时也能控制整体成本。
常见问题 FAQ
Q:R1和V3哪个更聪明?
这个问题没有绝对答案。在推理密集型基准测试(如MATH、AIME、代码竞赛题)上,R1的得分更高;在语言理解和生成类基准上,V3表现更均衡。”更聪明”取决于你定义的任务类型,对症下药才是关键。
Q:普通用户日常使用选哪个?
如果你主要用于写作、查资料、翻译、聊天,V3完全够用,而且响应更快。如果你经常需要解数学题、分析逻辑问题或调试复杂代码,R1值得优先考虑。
Q:通过API调用时如何选择模型版本?
DeepSeek官方API提供了deepseek-reasoner(对应R1)和deepseek-chat(对应V3)两个端点。根据任务类型在请求时指定对应的model参数即可。建议在项目初期用两个模型分别跑一批测试样本,根据实际输出质量和延迟数据做最终决策。
Q:R1的推理过程会影响输出长度吗?
会。R1在输出最终答案之前会生成一段思考过程(thinking tokens),这部分内容会增加总token消耗。部分API接口允许你选择是否在响应中返回思考过程,如果只需要最终答案,可以关闭该选项以节省成本。
Q:DeepSeek后续版本会合并R1和V3的能力吗?
从行业趋势来看,推理能力与通用生成能力的融合是大方向。但目前两款模型仍有明显的能力侧重,在新版本发布之前,按任务类型分别调用仍是最优策略。
总结:建立你自己的选型判断框架
根据任务类型选择DeepSeek R1还是V3,核心逻辑可以归结为一个问题:这个任务需要”想清楚”还是”说清楚”?
需要多步推导、逻辑验证、精确计算的任务,选R1。需要流畅表达、快速生成、广泛覆盖的任务,选V3。两者都不是万能的,但只要选对了场景,都能给出远超预期的结果。
建议开发者在项目中建立一个简单的任务分类标签系统,将任务预先归类为”推理型”或”生成型”,再映射到对应模型。这样不仅能提升输出质量,也能在规模化调用时有效控制成本。随着你对两款模型的使用经验积累,这套判断会越来越直觉化。
想了解更多AI工具和技巧?欢迎访问红烁AI 培训,红烁 AI 中转站,获取最新AI资讯和实用教程。