
背景介绍:DeepSeek R1 与 V3 是什么?
红烁AI 培训,红烁 AI 中转站为您整理:DeepSeek 是由深度求索(DeepSeek AI)推出的大语言模型系列,凭借极具竞争力的性能和开源策略,在全球 AI 社区引发广泛关注。其中,DeepSeek V3 和 DeepSeek R1 是目前最受开发者关注的两款旗舰模型,但它们的设计目标截然不同,速度表现也因此存在本质差异。
DeepSeek V3 是一款通用型大语言模型,采用混合专家架构(MoE),拥有 671B 总参数,每次推理激活约 37B 参数。它的设计目标是在广泛任务上提供快速、流畅的响应,适合代码生成、文本创作、问答对话等高频场景。
DeepSeek R1 则是一款专为复杂推理任务打造的模型,内置”思维链”(Chain-of-Thought)机制。在给出最终答案之前,R1 会进行大量内部推理步骤,这意味着它在处理数学证明、逻辑推断、代码调试等任务时更加准确,但也因此带来了额外的计算开销。
理解这一根本差异,是正确解读 DeepSeek R1 vs V3 速度对比的前提。
核心对比:DeepSeek R1 vs V3 速度差异详解
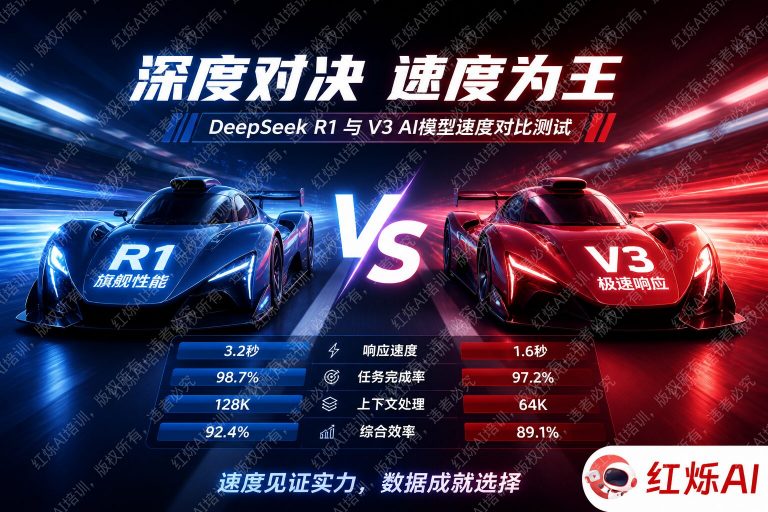
1. Token 生成速度(Output Tokens/s)
从原始 Token 输出速度来看,DeepSeek V3 明显快于 R1。根据多个第三方平台(包括 Artificial Analysis、OpenRouter 等)的基准测试数据:
- DeepSeek V3:平均输出速度约为 60–80 tokens/秒(官方 API,高峰期有所波动)
- DeepSeek R1:平均输出速度约为 20–40 tokens/秒,复杂推理任务下可能更低
这一差距并非 R1 的技术缺陷,而是其推理机制的必然结果。R1 在输出可见内容之前,会先生成大量”思考 token”(thinking tokens),这部分计算对用户不可见,但实实在在地消耗了时间和算力。
2. 首 Token 延迟(Time to First Token, TTFT)
首 Token 延迟直接影响用户的”感知速度”。测试数据显示:
- DeepSeek V3:TTFT 通常在 0.5–2 秒之间,响应感觉流畅
- DeepSeek R1:由于需要先完成内部推理,TTFT 可能达到 5–30 秒,复杂问题甚至更长
对于需要实时交互的应用场景,这个差距会让用户体验产生明显落差。
3. 完整响应时间(End-to-End Latency)
综合考虑推理深度和输出长度,两款模型的完整响应时间对比如下:
- 简单问答任务:V3 约 2–5 秒,R1 约 10–30 秒
- 中等复杂度任务(如代码生成):V3 约 5–15 秒,R1 约 20–60 秒
- 高难度推理任务(如数学证明):V3 约 10–20 秒,R1 约 30–120 秒
数字背后的逻辑很清晰:任务越简单,V3 的速度优势越明显;任务越复杂,R1 的准确性优势越能弥补速度劣势。
4. 架构层面的速度影响因素
除了推理机制,以下架构因素也影响两者的速度表现:
- MoE 激活参数:V3 每次只激活约 37B 参数,推理效率高;R1 同样基于 MoE,但推理链路更长
- 上下文窗口:两者均支持 128K 上下文,长文本处理时速度差异会进一步放大
- 量化版本:本地部署时,R1 和 V3 均有 Q4、Q8 等量化版本,量化后速度提升显著,但 V3 仍保持相对优势
实际应用:哪个场景选哪个模型?
选 DeepSeek V3 的场景
- 实时对话与客服机器人:需要快速响应,V3 的低延迟体验更佳
- 内容创作与文案生成:写文章、写邮件、写营销文案,V3 速度快且质量稳定
- 代码补全与 IDE 集成:开发者需要即时反馈,V3 更适合 Copilot 类场景
- 高并发 API 调用:成本敏感型业务,V3 的吞吐量更高,单位成本更低
- 日常问答与信息检索:不需要深度推理的通用任务,V3 完全够用
选 DeepSeek R1 的场景
- 数学与科学计算:竞赛级数学题、物理推导,R1 的准确率远超 V3
- 复杂代码调试:需要逐步分析 bug 根因,R1 的推理链路能发现 V3 遗漏的问题
- 逻辑推理与策略规划:多步骤决策、博弈分析,R1 更可靠
- 学术研究辅助:论文分析、实验设计,R1 的深度思考能力更有价值
- 对准确性要求高于速度的任务:宁可等 30 秒得到正确答案,也不要 3 秒得到错误答案
常见问题 FAQ
Q1:DeepSeek R1 比 V3 慢多少倍?
在大多数任务中,R1 的完整响应时间是 V3 的 3–6 倍。简单任务差距较小,复杂推理任务差距可能超过 10 倍。但需要注意,这种”慢”是用准确性换来的,不是纯粹的性能劣势。
Q2:本地部署时速度对比会变化吗?
会有变化,但趋势不变。本地部署受硬件限制(GPU 显存、带宽),两者速度都会下降,但 V3 仍然快于 R1。使用量化版本(如 Q4_K_M)可以显著提升速度,推荐在消费级 GPU 上优先尝试 V3 的量化版本。
Q3:DeepSeek R1 的”思考时间”可以关闭吗?
部分 API 提供商支持通过参数控制 R1 的推理深度,但完全关闭思维链会让 R1 退化为普通模型,失去其核心优势。如果你不需要深度推理,直接使用 V3 是更合理的选择。
Q4:哪个模型更便宜?
从官方 API 定价来看,DeepSeek V3 的价格通常低于 R1,且因为响应更快,同等任务量下的总费用更低。R1 因为消耗更多计算资源,定价相对较高。
Q5:未来版本会改善 R1 的速度吗?
DeepSeek 团队持续优化推理效率。随着推测解码(Speculative Decoding)、更高效的 MoE 路由等技术的应用,R1 后续版本的速度有望提升,但”推理换准确性”的核心权衡不会消失。
总结
在 DeepSeek R1 vs V3 速度对比中,结论很明确:DeepSeek V3 在速度上全面领先 R1,Token 生成速度快 2–3 倍,首 Token 延迟低 5–10 倍,整体响应时间短 3–6 倍。
但速度不是选择模型的唯一标准。V3 的快是以”不深度思考”为代价的,R1 的慢是”认真推理”的体现。正确的使用姿势是:把 V3 当作高效的通用助手,把 R1 当作解决硬核问题的专家顾问。
对于大多数日常开发和内容场景,DeepSeek V3 是更实用的选择;当你面对数学、逻辑、复杂代码等需要精确推理的任务时,DeepSeek R1 的等待时间完全值得。理解这一差异,才能真正发挥两款模型各自的价值。
想了解更多AI工具和技巧?欢迎访问红烁AI 培训,红烁 AI 中转站,获取最新AI资讯和实用教程。