
背景:DeepSeek 为什么要推出两个不同的模型?
红烁AI 培训,红烁 AI 中转站为您整理:2025 年初,DeepSeek 相继发布了 V3 和 R1 两款大语言模型,在全球 AI 社区引发广泛关注。很多用户在实际使用中发现,面对同一个问题,两个模型给出的答案质量和风格差异明显——有时 R1 更准确,有时 V3 更流畅。
这种差异并非偶然,而是两款模型在设计目标上就存在根本性的分歧。理解这一点,是学会怎么区分 DeepSeek R1 和 V3 使用场景的第一步。
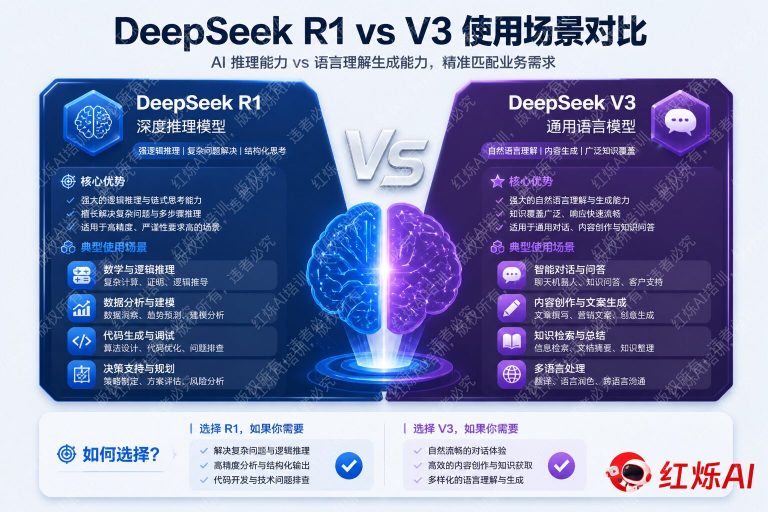
DeepSeek V3 是一款面向通用场景的大语言模型,采用混合专家架构(MoE),参数规模达 671B,激活参数约 37B,主打高效、快速的对话与内容生成能力。而 DeepSeek R1 则在 V3 的基础上,通过强化学习(GRPO)进行了专项训练,赋予模型”链式思维”(Chain-of-Thought)推理能力,专为复杂逻辑任务设计。
核心差异:R1 和 V3 的本质区别是什么?
1. 思维方式不同
这是两者最根本的区别。V3 的工作方式更接近”直觉型”——接收问题后快速生成答案,适合大多数不需要严密推导的任务。R1 则是”分析型”——在给出最终答案之前,会在内部进行多步骤的推理链条,类似于人类解题时打草稿的过程。
- V3:输入 → 直接输出答案
- R1:输入 → 内部推理链(thinking tokens)→ 输出答案
这意味着 R1 在处理复杂问题时更可靠,但响应时间也相对更长,token 消耗更多。
2. 训练方式不同
V3 主要通过监督微调(SFT)和人类反馈强化学习(RLHF)训练,优化方向是对话流畅性和指令遵循能力。R1 则额外引入了基于规则的强化学习,模型会因为推理过程正确而获得奖励,这使它在数学证明、代码调试、逻辑推断等任务上具备显著优势。
3. 性能侧重不同
根据 DeepSeek 官方评测数据:
- 在 MATH-500 数学基准测试中,R1 得分 97.3%,V3 得分 90.2%
- 在 Codeforces 编程竞赛评级中,R1 达到 Expert 级别,V3 相对较低
- 在 MMLU 通用知识测试中,两者差距较小,V3 响应速度更快
- 在创意写作、内容生成类任务中,V3 的输出风格更自然流畅
实际应用:怎么区分 DeepSeek R1 和 V3 的使用场景
优先选择 DeepSeek R1 的场景
当你的任务需要严密的逻辑推导、多步骤计算或系统性分析时,R1 是更合适的选择。
- 数学与竞赛题:高考数学、AMC/AIME 竞赛题、微积分推导、线性代数证明等,R1 的逐步推理能显著减少计算错误。
- 代码调试与算法设计:当你需要找出代码中的逻辑 bug、设计复杂算法或分析时间复杂度时,R1 的推理能力能帮你追踪每一步的执行逻辑。
- 逻辑推理与谜题:侦探推理、条件判断题、哲学论证分析等,R1 不容易在中间步骤出现跳跃性错误。
- 科学研究辅助:物理公式推导、化学反应机理分析、统计学假设检验等需要严谨性的学术任务。
- 金融与数据分析:财务模型构建、量化策略逻辑验证、复杂 SQL 查询优化等。
优先选择 DeepSeek V3 的场景
当你的任务更注重效率、流畅度和创意表达时,V3 是更经济实用的选择。
- 内容创作与写作:文章撰写、营销文案、社交媒体内容、故事创作等,V3 的语言风格更自然,生成速度更快。
- 日常问答与知识检索:查询历史事件、解释概念、获取建议等不需要复杂推理的问题,V3 响应更迅速。
- 翻译与语言处理:多语言翻译、文本润色、语法纠错、摘要生成等语言类任务,V3 表现稳定且高效。
- 头脑风暴与创意发散:产品命名、活动策划、创意方案生成等需要大量发散性输出的场景,V3 更适合快速迭代。
- 客服与对话系统:构建需要快速响应的对话应用时,V3 的低延迟特性更具优势。
- 代码生成(非调试):快速生成样板代码、API 调用示例、简单脚本等,V3 足够胜任且成本更低。
一张表帮你快速决策
如果你还是拿不准,可以用这个简单的判断逻辑:任务需要”算出来”还是”写出来”?需要算的选 R1,需要写的选 V3。需要又算又写的复杂任务,可以先用 R1 完成推理部分,再用 V3 润色输出。
常见问题 FAQ
Q1:R1 比 V3 更智能吗?
不能简单地说谁更智能。R1 在推理密集型任务上更强,V3 在通用对话和内容生成上更均衡。选错场景的话,R1 也可能给出过度复杂的回答,V3 也可能在简单问题上表现得更直接清晰。智能与否取决于任务匹配度。
Q2:R1 响应慢是因为模型更大吗?
不完全是。R1 响应慢的主要原因是它会生成大量内部推理 token(thinking tokens),这些推理过程在部分界面中不可见,但实际上消耗了计算资源和时间。模型参数规模上,R1 和 V3 基础架构相近。
Q3:API 调用时,两者的费用有差异吗?
有差异。由于 R1 生成的 token 数量更多(包含推理链),在相同任务下,R1 的 API 调用费用通常高于 V3。对于成本敏感的应用场景,建议优先评估 V3 是否能满足需求。
Q4:可以用 V3 做数学题吗?
可以,但准确率不如 R1。对于高中及以下难度的数学题,V3 通常能给出正确答案。但涉及多步骤证明、竞赛级别题目或需要严格验证的计算时,建议切换到 R1 以降低出错概率。
Q5:DeepSeek 官方有推荐的使用方式吗?
DeepSeek 官方文档建议:将 R1 定位为”思考型”模型用于推理任务,将 V3 定位为”执行型”模型用于生成任务。在实际产品开发中,也可以将两者结合使用——用 R1 进行规划和推理,用 V3 进行最终内容输出。
总结
怎么区分 DeepSeek R1 和 V3 的使用场景,核心逻辑只有一句话:R1 用来”想清楚”,V3 用来”说明白”。
遇到数学、代码调试、逻辑推理这类需要严密思考的任务,选 R1;遇到写作、翻译、问答、创意生成这类需要流畅表达的任务,选 V3。两者并非竞争关系,而是互补的工具组合。
随着 DeepSeek 持续迭代,两款模型的能力边界也在不断演进。建议收藏本文,并在实际使用中根据任务类型灵活切换,才能真正发挥出 DeepSeek 系列模型的最大价值。
想了解更多AI工具和技巧?欢迎访问红烁AI 培训,红烁 AI 中转站,获取最新AI资讯和实用教程。